最近,在业务上遇到一个问题:公司的会员卡号要支持合并了,一位顾客注册了 A 、 B 两张会员卡,系统支持将 A 会员卡合并到 B 会员卡,A 会员卡的会员权益和相关记录将在合并发生后转移到 B 会员卡。同时,A 到 B 的合并关系会记录在一张数据表里。现在,要实现通过 sql 查询出 A 会员卡合并到 B 会员卡这样的关系。
若仅仅是由 A 合并到 B,则很容易实现。偏偏这里的合并未做限制,由于羊毛党猖獗,加上营销部门有时为了数据好看,现实中往往存在这样的合并路径:A 合并到 B,B 合并到 C 、 E 合并到 C 、 C 合并到 D,这样 A 最后合并到了 D,E 最后也合并到了 D 。通过 SQL 查询这样的合并结构,这里需要用到递归查询。
with 查询
使用递归查询前先了解下 with 查询,with 提供了一种方式来书写在一个大型查询中使用的辅助语句。这些语句通常被称为公共表表达式或 CTE,它们可以被看成是定义在当前查询中存在的临时表。例如:
with a as ( --先用 with 创建一个名为 a 的对班级男同学的查询
select stu.stu_num,stu.stu_name from student as stu
where stu.stu_sex='男'
)
--接着引用这个临时表找到名字叫 “李岩” 的这位同学
select stu_num,stu_name from a where stu_name='李岩';
在查询中使用 with 有诸多好处:
- 使 sql 语句结构简单,层次分明:特别是大型查询,动辄几百行,这种情况下出现几个长嵌套,不要说给别人看了,一段时间后连自己都搞不清楚了。若使用 with 查询替代嵌套的子查询其模块化表达,结构清晰,易于阅读和理解;
- 提升效率:with 查询的另一个有用的特性是在每一次的父查询执行中它们通常只被计算一次,即便它们被父查询或兄弟 with 查询多次引用。 因此,在多个地方需要的昂贵计算可以被放在一个 with 查询中来避免冗余工作。比如要对某组指定的会员做不同维度的数据分析,那么,对 “这组指定人员” 就可用使用 with 查询,其他兄弟查询直接引用结果即可,当需要对 “这组指定人员” 进行调整时,单独调整 with 查询就行了。
- 递归查询:完成递归查询是 with 语句最重要的特性之一,也接下来要详细介绍的。
递归查询
通过对 with 语句增加 RECURSIVE 修饰符以实现递归查询的目的,常用于层级结构查询,如组织层级、人员层级、物料清单等场景,递归查询格式如下:
with RECURSIVE recursive_name as (
非递归查询 --必须
union --必须,也可以是 union all
递归查询 --必须
)
select * from recursive_name;
下面以本次面对的问题展开:
创建会员合并记录表 cust_merge_dtl
CREATE table if not EXISTS cust_merge_dtl (
merge_id integer, --id
src_cust_id integer, --合并前的会员卡
desc_cust_id integer, --合并后的会员卡
op_time TIMESTAMP --合并时间
);写入几条会员合并记录
insert into cust_merge_dtl (merge_id,src_cust_id,desc_cust_id,op_time)
VALUES ('1','10056','10071','2019-09-21 8:38:17');
insert into cust_merge_dtl (merge_id,src_cust_id,desc_cust_id,op_time)
VALUES ('2','10071','10092','2020-03-12 16:18:55');
insert into cust_merge_dtl (merge_id,src_cust_id,desc_cust_id,op_time)
VALUES ('3','10088','10092','2020-11-11 10:08:27');
insert into cust_merge_dtl (merge_id,src_cust_id,desc_cust_id,op_time)
VALUES ('4','10092','10112','2020-12-30 18:30:06');
insert into cust_merge_dtl (merge_id,src_cust_id,desc_cust_id,op_time)
VALUES ('5','10010','10112','2021-03-12 12:44:46');查询会员合并记录表 cust_merge_dtl
select * from cust_merge_dtl;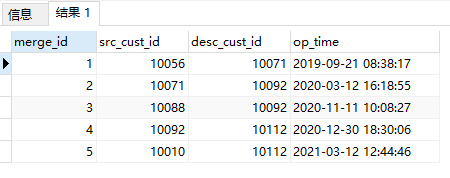
如上图所示,以 10056 会员卡为例,它只有一条合并记录,即 10056->10071,但是 10071 紧接着又做了一次合并,10071->10092,最后 10092 合并到了 10112,推算出 10056 最终合并到了 10112,完整的合并路径是这样的:10056 --> 10071 --> 10092 --> 10112
现在用递归查询生成这种合并关系。
with recursive cust_merge as (
select dtl1.src_cust_id as original_cust_id,--初始会员卡
dtl1.src_cust_id,--合并前的会员卡
dtl1.desc_cust_id,--合并后的会员卡
dtl1.op_time
from cust_merge_dtl dtl1 where dtl1.src_cust_id='10056' --非递归查询,此处的查询结果构成整个递归查询的基本结果形式
union
select cm.original_cust_id,dtl2.src_cust_id,dtl2.desc_cust_id,dtl2.op_time
from cust_merge cm
inner join cust_merge_dtl dtl2 on cm.desc_cust_id = dtl2.src_cust_id --递归查询
)
select * from cust_merge;
得到原始会员卡及过程中每一次的变动记录。
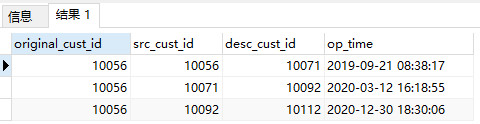
递归查询的执行过程是这样的:
- 查询首先从执行一次非递归查询开始,非递归查询的查询结果被保存在一个临时表中作为输出(本次查询以及之后的每次递归查询,生成的输出结果都将被保存在这个临时表中),以供之后的递归查询引用(通过紧跟 recursive 关键字的名字引用,示例通过 cust_merge 引用);
- 递归查询部分引用临时表作为输入,执行递归查询,生成的递归查询输出仍被保存在这个临时表中;
- 当本次递归输出不为空时,回到步骤 2,循环执行递归查询,直到递归输出结果为空,循环停止,递归结束;
- 最后的结果可以简单地认为是步骤 1 的查询结果加上步骤 2 的每次递归输出结果的并集(是否会去重复,这取决于非递归查询部分和递归查询部分两者之间使用的是 union 还是 union all,union 会去重复,union all 则不做去重)。
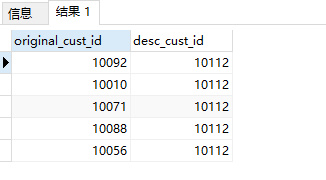
如果不关注中间的过程只想知道这些合并的会员卡最终合并到哪个会员卡了,稍作调整即可:
with recursive cust_merge as (
select dtl1.src_cust_id as original_cust_id,dtl1.src_cust_id,dtl1.desc_cust_id,dtl1.op_time
from cust_merge_dtl dtl1 --where dtl1.src_cust_id='10056'
union all
select cm.original_cust_id,dtl2.src_cust_id,dtl2.desc_cust_id,dtl2.op_time
from cust_merge cm
inner join cust_merge_dtl dtl2 on cm.desc_cust_id = dtl2.src_cust_id
),
last_record as (
--原始会员对应的最新迭代合并记录
select cm.original_cust_id,max(op_time) as last_merge_time
from cust_merge cm
GROUP BY cm.original_cust_id
)
select cm.original_cust_id,cm.desc_cust_id
from cust_merge cm
where exists (
select 1 from last_record lr where lr.last_merge_time=cm.op_time and lr.original_cust_id=cm.original_cust_id
);
界面有点熟悉 用的 Navicat Premium ?
@叶开楗 嗯 就是它